
初めまして!Hurariと申します。
今回はPythonという言語を使った「回帰分析の自動化ツール」をご紹介いたします。
本記事をご覧の皆さんは、仕事や大学でデータ分析を用いることが多いと思います。
例えば、いろんなデータの相関関係や因子の影響度合いを確認したい時など。
しかし、これをエクセルでやろうとするとデータ整理や処理に多くの時間がかかりますよね…。
これをパッとグラフ化してくれないものか。
そこで、面倒な作業は自動化してしまおう!ということで回帰分析ツールの作成をご紹介します。
少しでも、データ分析にお困りの方のお役に立てれば幸いです。
この記事におすすめの方は?
- データ分析の作業が面倒だと感じている方
- 自動化ツールの作成に興味のある方
- 会社(学校)の業務効率化をしたい方
※私自身、2021年からプログラミングの勉強を始めたため、コード記述に改善の余地があるかもしれませんが、ご容赦ください。
目次
回帰分析の自動化ツールのご紹介
はじめに、今回ご紹介するツールで普段のデータ分析がどのように自動化できるのかをご紹介します。
集めたデータを自動で分析しよう!
- 自動化ツールを立ち上げる
- データ分析を行うエクセルを選択する
- 目的変数と説明変数を設定する
- 必要によって分類分けの質的データを選択する
- 回帰分析を実行する
この自動化ツールを活用することで時間をかけずにサクッとデータ分析ができます!
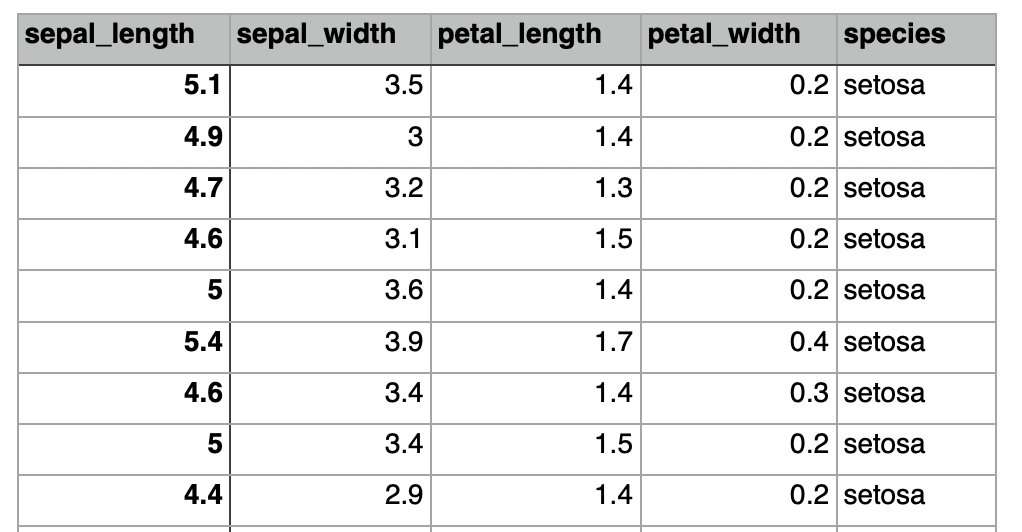
例えば、上記のirisデータセット(機械学習などで用いられる有名なデータセットです)を使って分析を行うとします。
※irisはアヤメという花のことで、ギリシャ語では虹を意味するそうです。

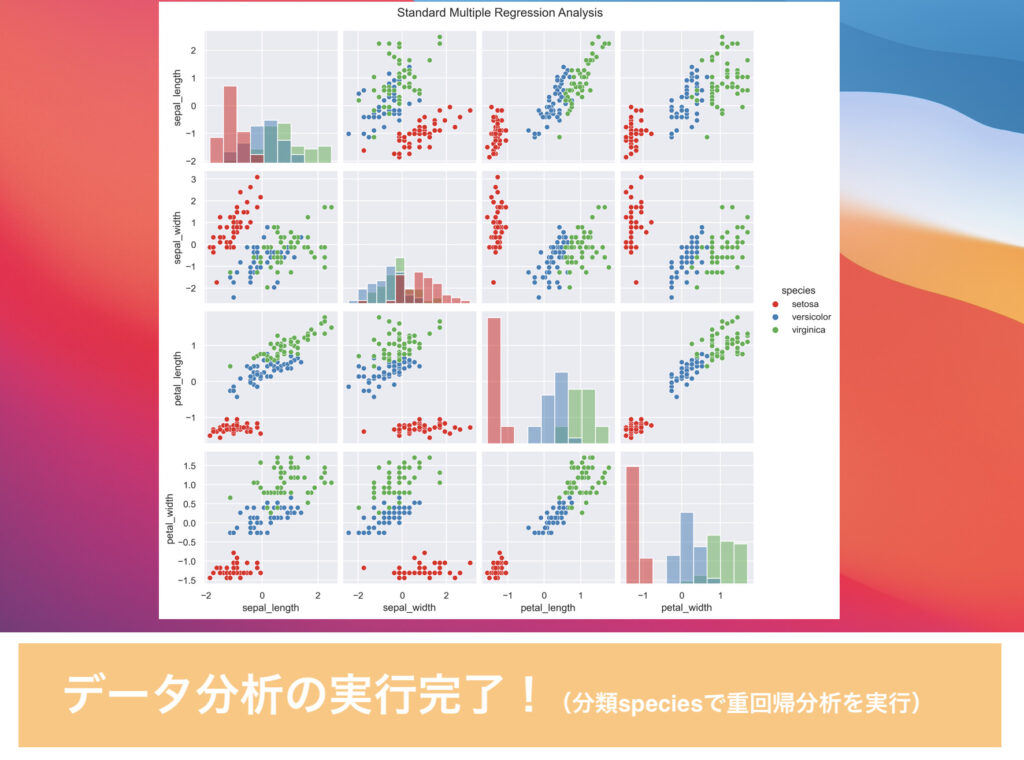
簡単な操作でグラフ表示ができた!
このほかにも「データの標準化」や、複数シートがあるエクセルを開く場合に「エクセルシートの更新」といった機能を搭載しています。
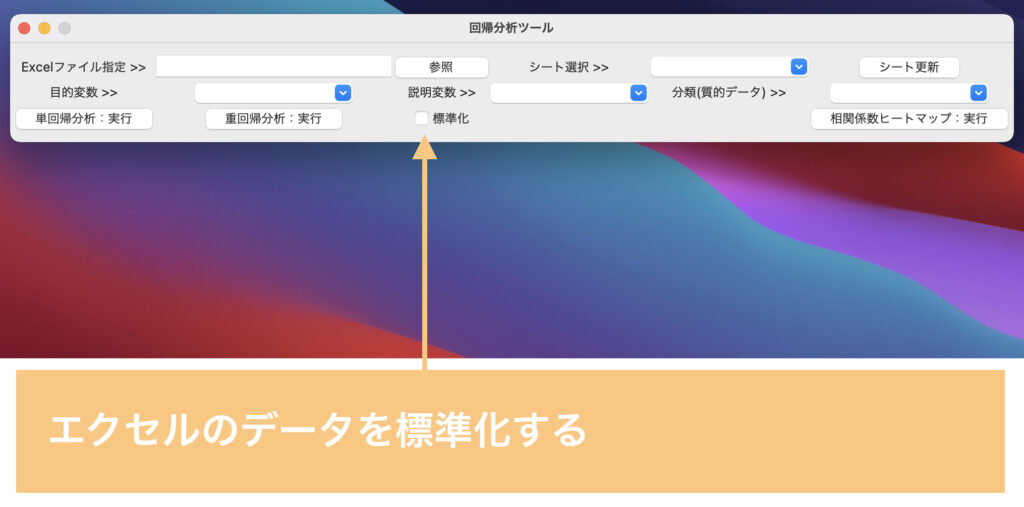

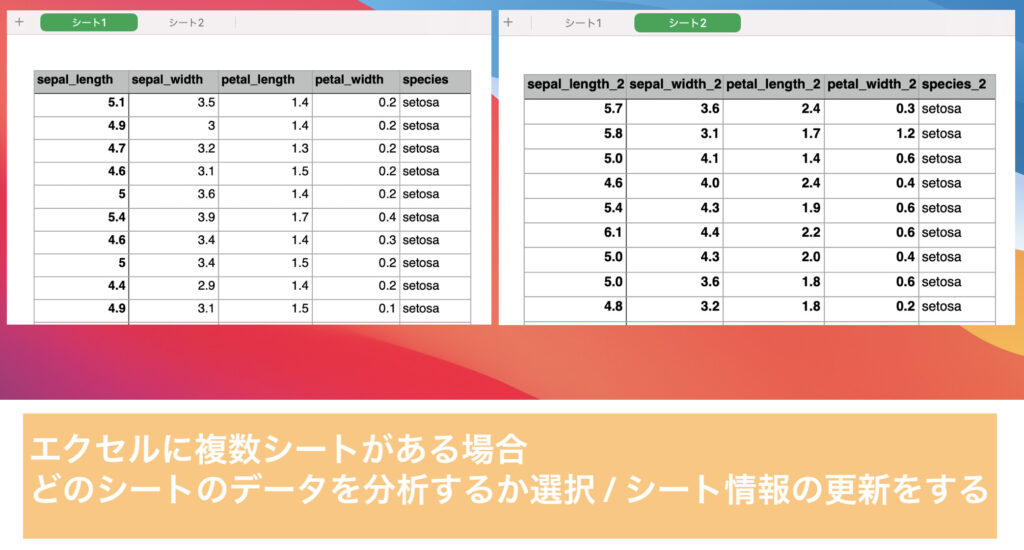
ここまでで、自動化ツールの使用方法をなんとなく理解いただけたかと思います。
また、この自動化ツールでは、画像で紹介したもの以外にも便利な機能があります。
それらを下記にまとめました!
データ分析の自動化ツールでできること
- 単回帰分析 / 重回帰分析の実行
- 相関係数のヒートマップ図の作成
- T値やP値の推定検定の結果表示
単回帰分析の実行では、散布図と偏回帰係数の結果を得ることができます。
グラフ中の実線は回帰式を示し、薄青色の範囲は95%信頼区間を表しています。

また、質的データの分類分けをすることで、それぞれのデータの関係性が視覚的に分かります。
ただし、ここで得られる回帰式は分類ごとに計算されたものではないため、注意して下さい。
(つまり、分類分けをしていない条件で単回帰分析を行った回帰式と同じ結果となります)
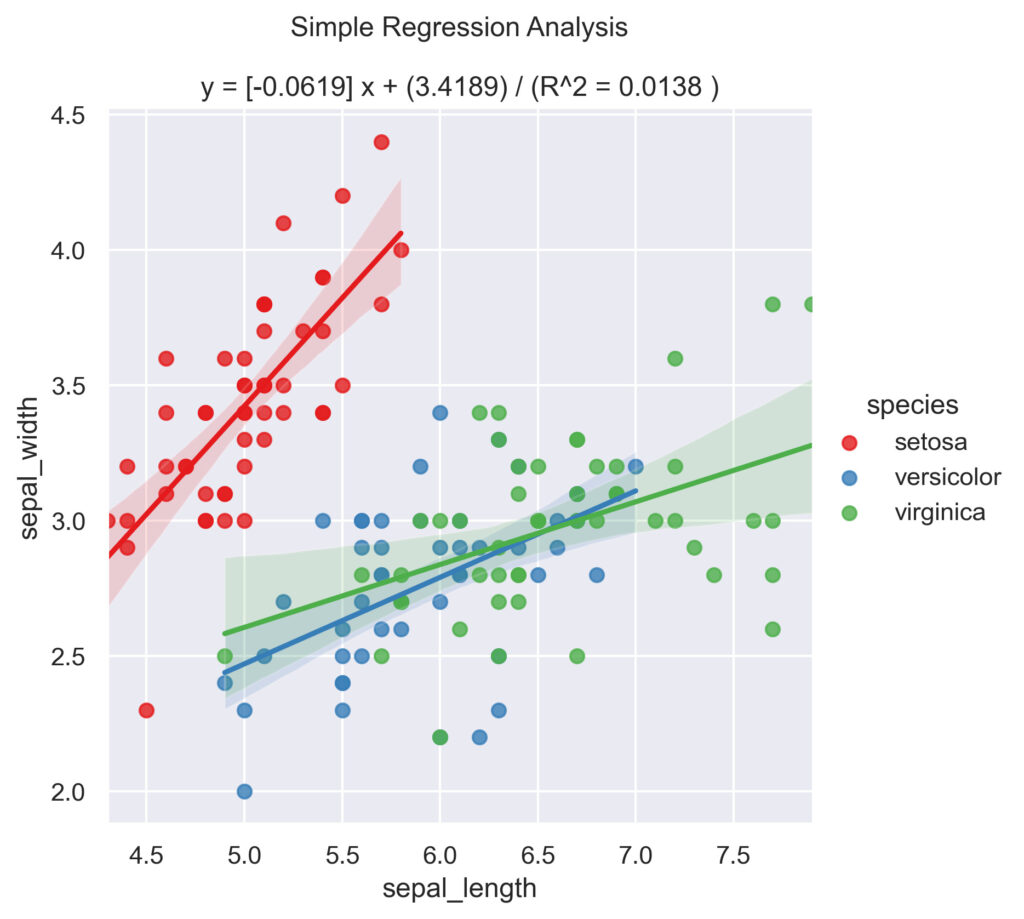
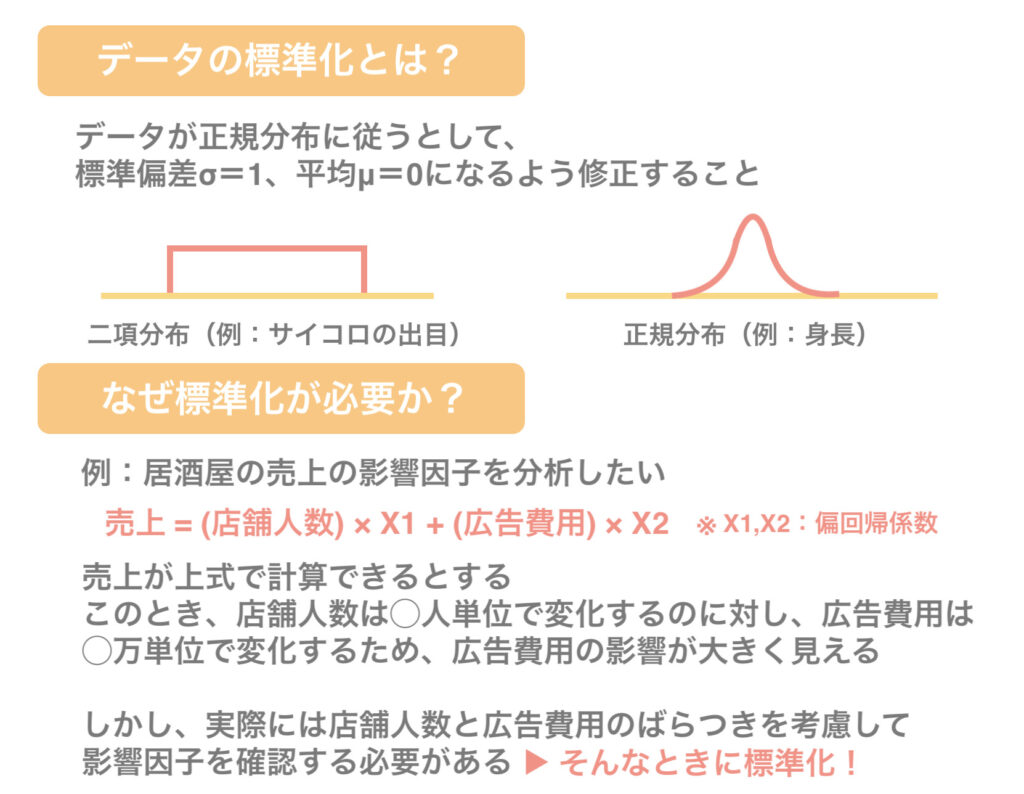
ちなみに、質的データってなんぞや?
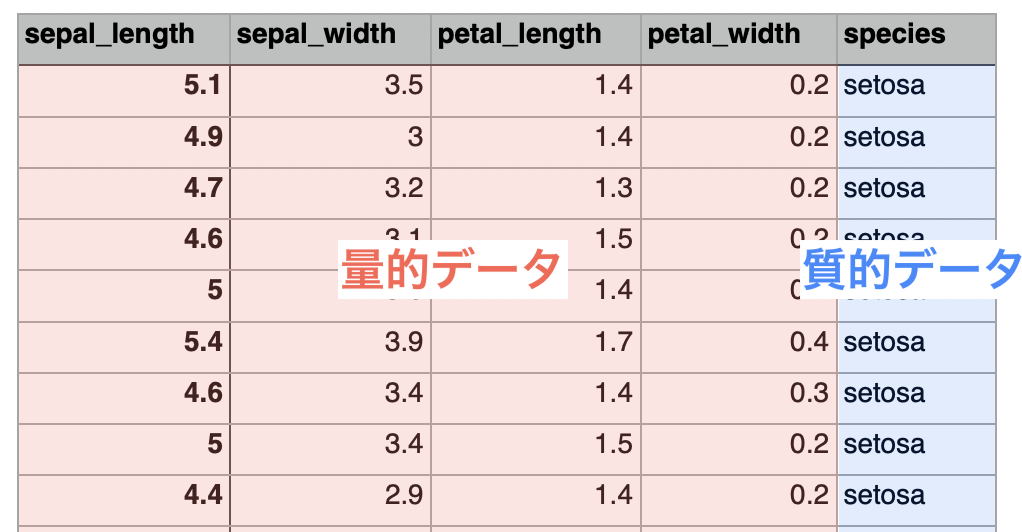
質的データとは、A地方、B地方といったように、数値で表現できないデータのことを指します。
今回のirisデータセットでは「species」が質的データにあたります。
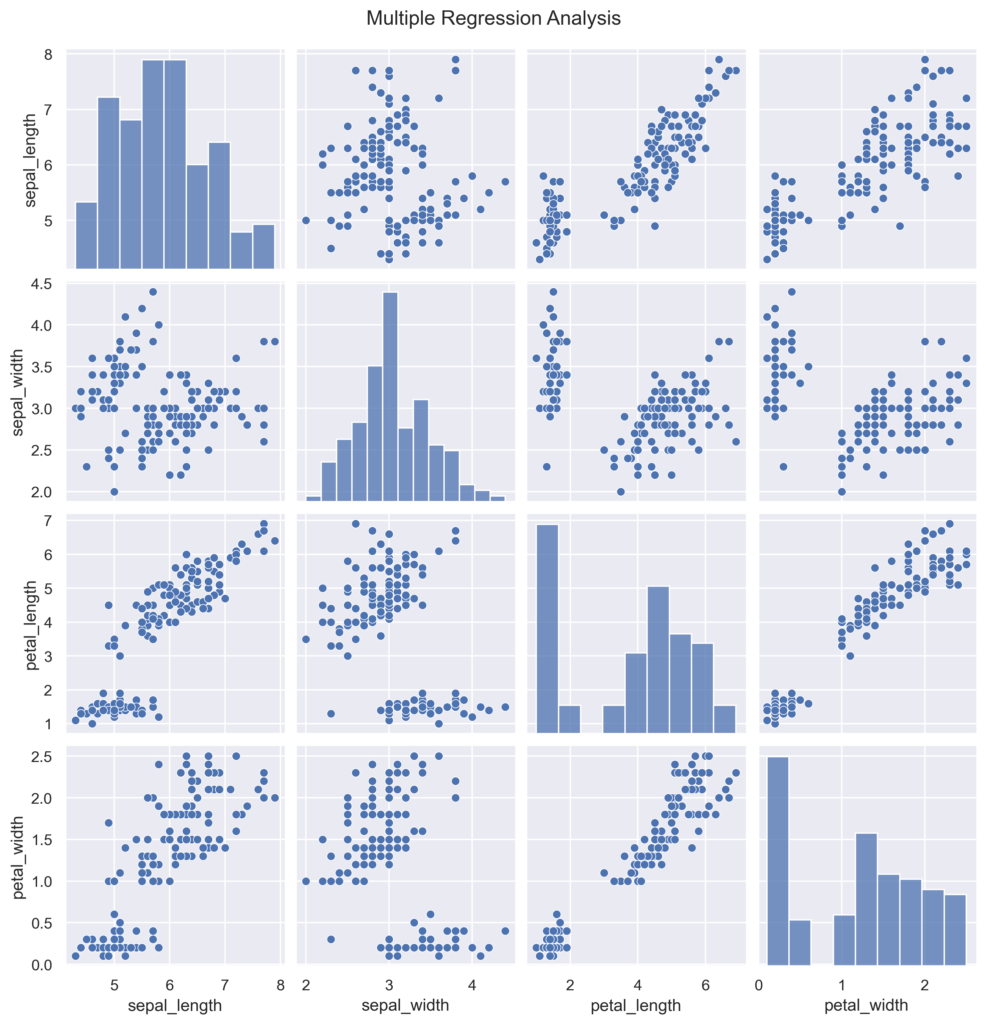
つづいて、重回帰分析の実行例です。
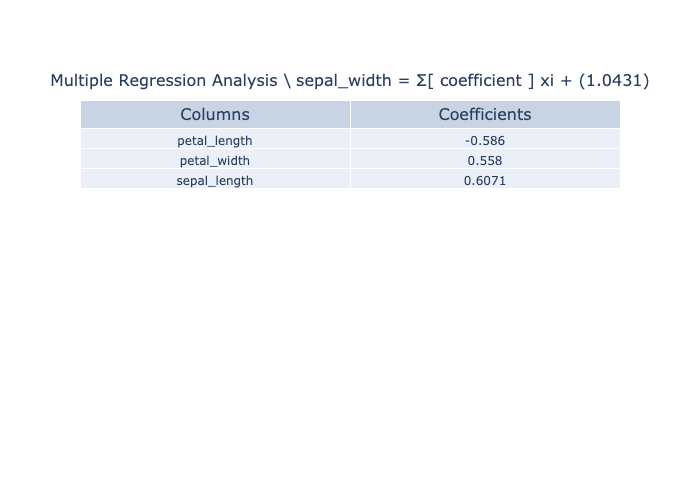
重回帰分析では、各パラメータを比較した散布図とヒストグラムを表示し、グラフとは別に偏回帰係数の結果を表として出力するようにしています。
相関係数ヒートマップ作成では、係数の関係を視覚的に確認することができます。

標準化を選択し、単回帰分析(もしくは重回帰分析)を実行した場合は、推定検定の結果をテキストデータで出力することができます。
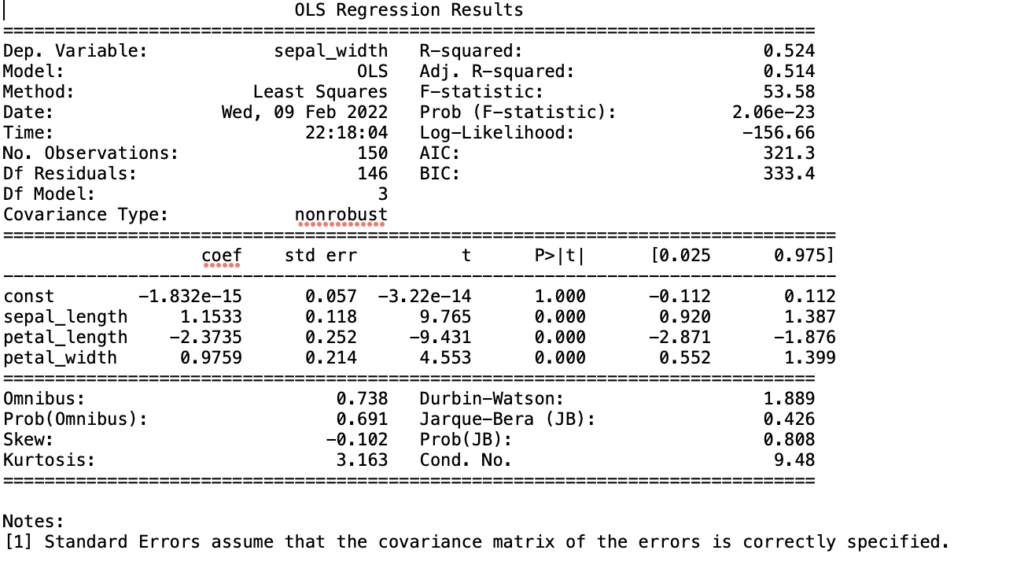
この出力結果の内容については、こちらの方の記事が非常にわかりやすいので、オススメです!
これらを駆使することで、データの予測や影響因子の抽出が容易にでき、必要なソリューションや新しく必要なデータを導き出すことができます!
コンサルやマーケティング、開発などさまざまな職種の方に役立つツールかと思います。
データ分析の自動化のコード
こちらのコードはPythonというインタープリンタ型の言語で作成しています。
インタープリンタ型って何?どこにコードをコピペするの?
このような疑問を持たれる方は、非常に簡単にですがこちらの記事で紹介しているので、ぜひご覧ください。

自動化のソースコード
さて、いよいよ自動化のソースコードになります。それがこちら!
### 使用するライブラリのインポート
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# %matplotlib inline
from sklearn import linear_model
import scipy
import japanize_matplotlib
import os
import tkinter as tk
import tkinter.ttk as ttk
from tkinter import Tk,StringVar,ttk,filedialog,messagebox,LEFT
import statsmodels.api as sm
import statsmodels.formula.api as smf
import plotly.graph_objects as go
root = tk.Tk()
root.title('回帰分析ツール')
root.resizable(False, False)
### エクセル参照ボタン操作時
def excel_ref_clicked():
global df_data
global dummy_df_data
fTyp = [("EXCELファイル","*.xlsx")]
iDir = os.path.abspath(os.path.dirname('__file__'))
file_path = filedialog.askopenfilename(filetypes = fTyp, initialdir = iDir)
file1.set(file_path)
df_data = nan_delet()
col_list = list()
dummy_list = list()
for i in df_data.columns:
if type(df_data[i].loc[2]) != str:
col_list.append(i)
else:
dummy_list.append(i)
dummy_df_data = df_data
for j in col_list:
dummy_df_data = dummy_df_data.drop(j, axis = 1)
for k in dummy_list:
df_data = df_data.drop(k, axis = 1)
dummy_list.append('')
combobox1['values'] = tuple(col_list)
combobox1.set(col_list[0])
combobox2['values'] = tuple(col_list)
combobox2.set(col_list[1])
combobox3['values'] = tuple(dummy_list)
combobox3.set('')
df_data_sheet_all = pd.read_excel(file1.get(), sheet_name = None)
sheet_list = list()
for l in df_data_sheet_all.keys():
sheet_list.append(l)
combobox4['values'] = tuple(sheet_list)
combobox4.set(sheet_list[0])
### シートの更新をクリック時
def sheet_select_clicked():
global df_data
global dummy_df_data
if os.path.isfile(file1.get()):
df_data = nan_delet()
col_list = list()
dummy_list = list()
for i in df_data.columns:
if type(df_data[i].loc[2]) != str:
col_list.append(i)
else:
dummy_list.append(i)
dummy_df_data = df_data
for j in col_list:
dummy_df_data = dummy_df_data.drop(j, axis = 1)
for k in dummy_list:
df_data = df_data.drop(k, axis = 1)
dummy_list.append('')
combobox1['values'] = tuple(col_list)
combobox1.set(col_list[0])
combobox2['values'] = tuple(col_list)
combobox2.set(col_list[1])
combobox3['values'] = tuple(dummy_list)
combobox3.set('')
else:
# エラー表示:存在していないファイル名の指定
dispmsg = "Excelファイルが存在していません。\n\n"
messagebox.showinfo('Failure', dispmsg)
### データフレームのNanを削除する
def nan_delet():
if combobox4.get() == "":
select = 0
else:
select = str(combobox4.get())
df_data = pd.read_excel(file1.get(), sheet_name = select)
#欠損値を含む列を削除
df_data_nan = df_data.dropna(how = 'any', axis = 1)
df_data_column = df_data.columns
df_data_nan_column = df_data_nan.columns
df_data_column_list = list()
for i in df_data_column:
if not i in "Unname":
df_data_column_list.append(i)
if len(df_data_nan) != len(df_data_column_list):
# 欠損データを除外したメッセージ表示
dispmsg = "欠損値を含むカラムを削除しました。\n\n"
messagebox.showinfo('information', dispmsg)
return df_data_nan
### 選択したエクセルファイルがあるフォルダに新しいディレクトリを作成
def make_new_directory():
excel_folder = os.path.dirname(file1.get())
#フォルダの所在確認
excel_folder_exist = os.path.isdir(excel_folder)
if excel_folder_exist:
# 画像の一時保存用フォルダを作成する
new_directory = excel_folder + "/Temp_Save_Folder"
if not os.path.exists(new_directory):
os.mkdir(new_directory)
else:
# エラー表示:存在していないフォルダ名の指定
dispmsg = "選択したフォルダが存在していません。\n\n再度、フォルダを選択してください。\n\n"
dispmsg += (excel_folder + "\n")
messagebox.showinfo('データを格納したフォルダが見つかりません', dispmsg)
new_directory = []
return new_directory
### 単回帰分析についての関数-回帰式を引数にして返す-
def simple_reg():
simple_reg_list = list()
# sklearn.linear_model.LinearRegression クラスを読み込み
clf = linear_model.LinearRegression()
# 説明変数に "combobox1" を利用
X = df_data.loc[:, [combobox1.get()]].values
# 目的変数に "combobox2" を利用
Y = df_data[combobox2.get()].values
# 予測モデルを作成
clf.fit(X, Y)
simple_reg_list.append(np.round(clf.coef_, 4)) #回帰係数
simple_reg_list.append(np.round(clf.intercept_, 4)) #切片(誤差)
simple_reg_list.append(np.round(clf.score(X, Y), 4)) #決定係数
return simple_reg_list
### 標準化した単回帰分析についての関数-回帰式を引数にして返す-
def standard_simple_reg():
standard_simple_reg_list = list()
# sklearn.linear_model.LinearRegression クラスを読み込み
clf = linear_model.LinearRegression()
stand_df_data = df_data.apply(lambda x: (x - np.mean(x)) / (np.std(x, ddof = 1))) #不偏分散
# 説明変数に "combobox1" を利用
x = stand_df_data.loc[:, [combobox1.get()]]
X = x.values
# 目的変数に "combobox2" を利用
y = stand_df_data[combobox2.get()]
Y = y.values
# 予測モデルを作成
clf.fit(X, Y)
standard_simple_reg_list.append(np.round(clf.coef_, 4))
standard_simple_reg_list.append(np.round(clf.intercept_, 4))
standard_simple_reg_list.append(np.round(clf.score(X, Y), 4))
return [stand_df_data, standard_simple_reg_list, x, y]
### 重回帰分析についての関数-回帰式を引数にして返す-
def multiple_reg():
multiple_reg_list = list()
# sklearn.linear_model.LinearRegression クラスを読み込み
clf = linear_model.LinearRegression()
# 説明変数に "combobox2以外" を利用
drop_data = df_data.drop(combobox2.get(), axis = 1)
X = drop_data.values
# 目的変数に "combobox2" を利用
Y = df_data[combobox2.get()].values
# 予測モデルを作成
clf.fit(X, Y)
multiple_reg_list.append(np.round(pd.DataFrame({"Columns":drop_data.columns, "Coefficients":clf.coef_}).sort_values(by = 'Coefficients'), 4)) #偏回帰係数
multiple_reg_list.append(np.round(clf.intercept_, 4)) #切片(誤差)
return multiple_reg_list
### 標準化した重回帰分析についての関数-回帰式を引数にして返す-
def standard_multiple_reg():
standard_multiple_reg_list = list()
# sklearn.linear_model.LinearRegression クラスを読み込み
clf = linear_model.LinearRegression()
stand_df_data = df_data.apply(lambda x: (x - np.mean(x)) / (np.std(x, ddof = 1)))
# 説明変数に "combobox2以外" を利用
x = stand_df_data.drop(combobox2.get(), axis = 1)
X = x.values
# 目的変数に "combobox2" を利用
y = stand_df_data[combobox2.get()]
Y = y.values
# 予測モデルを作成
clf.fit(X, Y)
standard_multiple_reg_list.append(np.round(pd.DataFrame({"Columns":x.columns, "Coefficients":clf.coef_}).sort_values(by = 'Coefficients'), 4))
standard_multiple_reg_list.append(np.round(clf.intercept_, 4))
return [stand_df_data, standard_multiple_reg_list, x, y]
### 回帰分析の結果
def result_summary(x, y):
# 定数項(y切片)を必要とする線形回帰のモデル式
X = sm.add_constant(x)
# 最小二乗法によるモデリング
model = sm.OLS(y, X)
result = model.fit()
# 重回帰分析の結果を表示
# result.summary()
return result
### 単回帰分析ボタンの実行
def simple_reg_start_clicked():
new_directory = make_new_directory()
if os.path.isfile(file1.get()):
# 標準化にチェックがない場合
if bool_check.get() == False :
simple_reg_list = simple_reg()
sns.set()
if combobox3.get() == '':
fig, ax = plt.subplots()
sns.regplot(x = combobox1.get(), y = combobox2.get(), data = df_data)
ax.grid(True)
ax.set_axisbelow(True)
save_fig_name = 'X_' + str(combobox1.get()) + '_Y_' + str(combobox2.get())
elif combobox3.get() != '':
hue_df_data = pd.concat([df_data, dummy_df_data[combobox3.get()]], axis = 1)
sns.lmplot(x = combobox1.get(), y = combobox2.get(), data = hue_df_data, hue = combobox3.get(), palette = 'Set1')
save_fig_name = 'X_' + str(combobox1.get()) + '_Y_' + str(combobox2.get()) + '_hue_' + str(combobox3.get())
plt.title('Simple Regression Analysis\n\n' + 'y = ' + str(simple_reg_list[0]) + ' x + (' + str(simple_reg_list[1])+ ') / (R^2 = ' + str(simple_reg_list[2]) + ' )')
plt.rcParams["savefig.facecolor"] = "white"
root, ext = os.path.splitext(file1.get())
basename = os.path.basename(root)
plt.savefig(os.path.join(new_directory, basename + '_' + str(combobox4.get()) + '_SR_' + save_fig_name + '.png'), bbox_inches = 'tight', dpi = 300)
plt.show()
plt.close()
# メッセージ表示
print('Insert Pictures Success!')
dispmsg = "Success!\n\n指定のExcelデータから単回帰分析グラフを作成しました。\n\n"
dispmsg += "出力ファイル名:\n"
dispmsg += (new_directory + "\n")
messagebox.showinfo('Success', dispmsg)
# 標準化にチェックされている場合
elif bool_check.get() == True :
standard_simple_reg_list = standard_simple_reg()
plot_data = standard_simple_reg_list[0]
sns.set()
if combobox3.get() == '':
fig, ax = plt.subplots()
sns.regplot(x = combobox1.get(), y = combobox2.get(), data = plot_data)
ax.grid(True)
ax.set_axisbelow(True)
save_fig_name = 'X_' + str(combobox1.get()) + '_Y_' + str(combobox2.get())
elif combobox3.get() != '':
hue_df_data = pd.concat([plot_data, dummy_df_data[combobox3.get()]], axis = 1)
sns.lmplot(x = combobox1.get(), y = combobox2.get(), data = hue_df_data , hue = combobox3.get(), palette = 'Set1' )
save_fig_name = 'X_' + str(combobox1.get()) + '_Y_' + str(combobox2.get()) + '_hue_' + str(combobox3.get())
plt.title('Standard Simple Regression Analysis\n\n' + 'y = ' + str(standard_simple_reg_list[1][0]) + ' x + (' + str(standard_simple_reg_list[1][1]) + ') / (R^2 = ' + str(standard_simple_reg_list[1][2]) + ' )')
plt.rcParams["savefig.facecolor"] = "white"
root, ext = os.path.splitext(file1.get())
basename = os.path.basename(root)
plt.savefig(os.path.join(new_directory, basename + '_' + str(combobox4.get()) + '_SSR_' + save_fig_name + '.png'), bbox_inches = 'tight', dpi = 300)
plt.show()
plt.close()
# 説明変数に "combobox1" を利用
x = standard_simple_reg_list[2]
# 目的変数に "combobox2" を利用
y = standard_simple_reg_list[3]
result = result_summary(x, y)
result.summary()
path_text = new_directory + '/' + basename + '_' + str(combobox4.get()) + '_SSR_text_' + save_fig_name + '.txt'
with open(path_text, mode = 'w') as f:
f.write(str(result.summary()))
# メッセージ表示
print('Insert Pictures Success!')
dispmsg = "Success!\n\n指定のExcelデータから標準化した単回帰分析グラフを作成しました。\n\n"
dispmsg += "出力ファイル名:\n"
dispmsg += (new_directory + "\n")
messagebox.showinfo('Success', dispmsg)
else:
# メッセージ表示
dispmsg = "Failure!\n\nExcelファイルが適切ではありませんでした。処理を中止します。\n\n"
dispmsg += "Excelファイルを再度選択して下さい。"
messagebox.showinfo('Failure', dispmsg)
### 重回帰分析ボタンの実行
def multiple_reg_start_clicked():
new_directory = make_new_directory()
if os.path.isfile(file1.get()):
# 標準化にチェックがない場合
if bool_check.get() == False :
multiple_reg_list = multiple_reg()
sns.set(style = 'darkgrid')
if combobox3.get() == '':
sns.pairplot(df_data)
save_fig_name = ''
elif combobox3.get() != '':
hue_df_data = pd.concat([df_data, dummy_df_data[combobox3.get()]], axis = 1)
sns.pairplot(hue_df_data, hue = combobox3.get(), diag_kind = 'hist', palette = 'Set1')
save_fig_name = '_hue_' + str(combobox3.get())
plt.suptitle('Multiple Regression Analysis', y = 1.02)
plt.rcParams["savefig.facecolor"] = "white"
root, ext = os.path.splitext(file1.get())
basename = os.path.basename(root)
plt.savefig(os.path.join(new_directory, basename + '_' + str(combobox4.get()) + '_MR' + save_fig_name + '.png'), bbox_inches = 'tight', dpi = 300)
plt.show()
plt.close()
df = multiple_reg_list[0]
#テーブルの作成
fig = go.Figure(data = [go.Table(columnwidth = [15, 15], #カラム幅の変更
header = dict(values = df.columns, align = 'center', font_size = 16),
cells = dict(values = df.values.T, align = 'center', font_size = 12))])
fig.update_layout(title = {'text': 'Multiple Regression Analysis' + ' \\ ' + str(combobox2.get()) + ' = Σ[ coefficient ] xi + (' + str(multiple_reg_list[1]) + ') ',
'y': 0.85, 'x': 0.5, 'xanchor': 'center'}) #タイトル位置の調整
fig.layout.title.font.size = 16 #タイトルフォントサイズの変更
fig.write_image(os.path.join(new_directory, basename + '_' + str(combobox4.get()) + '_MRc' + save_fig_name + '.png'), engine="kaleido", scale=10)
# メッセージ表示
print('Insert Pictures Success!')
dispmsg = "Success!\n\n指定のExcelデータから重回帰分析グラフを作成しました。\n\n"
dispmsg += "出力ファイル名:\n"
dispmsg += (new_directory + "\n")
messagebox.showinfo('Success', dispmsg)
# 標準化にチェックされている場合
elif bool_check.get() == True :
standard_multiple_reg_list = standard_multiple_reg()
sns.set(style = 'darkgrid')
plot_data = standard_multiple_reg_list[0]
if combobox3.get() == '':
sns.pairplot(plot_data)
save_fig_name = ''
elif combobox3.get() != '':
hue_df_data = pd.concat([plot_data, dummy_df_data[combobox3.get()]], axis = 1)
sns.pairplot(hue_df_data, hue = combobox3.get(), diag_kind = 'hist', palette = 'Set1')
save_fig_name = '_hue_' + str(combobox3.get())
plt.suptitle('Standard Multiple Regression Analysis', y = 1.02)
plt.rcParams["savefig.facecolor"] = "white"
root, ext = os.path.splitext(file1.get())
basename = os.path.basename(root)
plt.savefig(os.path.join(new_directory, basename + '_' + str(combobox4.get()) + '_SMR' + save_fig_name + '.png'), bbox_inches = 'tight', dpi = 300)
plt.show()
plt.close()
df = standard_multiple_reg_list[1][0]
#テーブルの作成
fig = go.Figure(data = [go.Table(columnwidth = [15, 15], #カラム幅の変更
header = dict(values = df.columns, align = 'center', font_size = 16),
cells = dict(values = df.values.T, align = 'center', font_size = 12))])
fig.update_layout(title = {'text': 'Standard Multiple Regression Analysis' + ' \\ ' + str(combobox2.get()) + ' = Σ[ coefficient ] xi + (' + str(standard_multiple_reg_list[1][1]) + ') ',
'y': 0.85, 'x': 0.5, 'xanchor': 'center'}) #タイトル位置の調整
fig.layout.title.font.size = 16 #タイトルフォントサイズの変更
fig.write_image(os.path.join(new_directory, basename + '_' + str(combobox4.get()) + '_SMRc' + save_fig_name + '.png'), engine="kaleido", scale=10)
# 説明変数に "combobox2以外" を利用
x = standard_multiple_reg_list[2]
# 目的変数に "combobox2" を利用
y = standard_multiple_reg_list[3]
result = result_summary(x, y)
result.summary()
path_text = new_directory + '/' + basename + '_' + str(combobox4.get()) + '_SMR_text' + save_fig_name + '.txt'
with open(path_text, mode = 'w') as f:
f.write(str(result.summary()))
# メッセージ表示
print('Insert Pictures Success!')
dispmsg = "Success!\n\n指定のExcelデータから標準化した重回帰分析グラフを作成しました。\n\n"
dispmsg += "出力ファイル名:\n"
dispmsg += (new_directory + "\n")
messagebox.showinfo('Success', dispmsg)
else:
# メッセージ表示
dispmsg = "Failure!\n\nExcelファイルが適切ではありませんでした。処理を中止します。\n\n"
dispmsg += "Excelファイルを再度選択して下さい。"
messagebox.showinfo('Failure', dispmsg)
### 相関係数ヒートマップの実行
def correlation_coeffi_start_clicked():
new_directory = make_new_directory()
if os.path.isfile(file1.get()):
cm = np.corrcoef(df_data.transpose())
plt.figure(figsize = (12, 10))
cmap = sns.color_palette("RdBu_r", 40)
sns.heatmap(cm, annot = True, cmap = cmap, xticklabels = df_data.columns, yticklabels = df_data.columns, vmax = 1, vmin = -1)
plt.rcParams["savefig.facecolor"] = "white"
root, ext = os.path.splitext(file1.get())
basename = os.path.basename(root)
plt.savefig(os.path.join(new_directory, basename + '_' + str(combobox4.get()) + '_CC.png'), bbox_inches = 'tight', dpi = 300)
plt.show()
plt.close()
# メッセージ表示
print('Insert Pictures Success!')
dispmsg = "Success!\n\n指定のExcelデータから相関係数のグラフを作成しました。\n\n"
dispmsg += "出力ファイル名:\n"
dispmsg += (new_directory + "\n")
messagebox.showinfo('Success', dispmsg)
else:
# メッセージ表示
dispmsg = "Failure!\n\nExcelファイルが適切ではありませんでした。処理を中止します。\n\n"
dispmsg += "Excelファイルを再度選択して下さい。"
messagebox.showinfo('Failure', dispmsg)
### メインフレームの作成と設置
frame = ttk.Frame(root)
frame.grid(column = 0, row = 0, sticky = tk.NSEW, padx = 5, pady = 10)
### 各種ウィジェットの作成
#エクセルラベルの作成
label1_str = StringVar()
label1_str.set('Excelファイル指定 >>')
label1 = ttk.Label(frame, textvariable = label1_str)
#参照パスラベルの作成
file1 = StringVar()
file1_entry = ttk.Entry(frame, width = 25, textvariable = file1)
button1 = ttk.Button(frame, text = "参照" , command = excel_ref_clicked)
#実行ボタンの作成
button1_execute = ttk.Button(frame, text = "単回帰分析:実行", command = simple_reg_start_clicked)
#実行ボタンの作成
button2_execute = ttk.Button(frame, text = "重回帰分析:実行", command = multiple_reg_start_clicked)
#実行ボタンの作成
button3_execute = ttk.Button(frame, text = "相関係数ヒートマップ:実行", command = correlation_coeffi_start_clicked)
#実行ボタンの作成
button4_execute = ttk.Button(frame, text = "シート更新", command = sheet_select_clicked)
#combobox1ラベルの作成
label2_str = StringVar()
label2_str.set('説明変数 >>')
label2 = ttk.Label(frame, textvariable = label2_str)
combobox1_str = StringVar()
combobox1 = ttk.Combobox(frame, width = 15, textvariable = combobox1_str)
combobox1['values'] = ()
combobox1.set('')
combobox1.bind('<<ComboboxSelected>>')
#combobox2ラベルの作成
label3_str = StringVar()
label3_str.set('目的変数 >>')
label3 = ttk.Label(frame, textvariable = label3_str)
combobox2_str = StringVar()
combobox2 = ttk.Combobox(frame, width = 15, textvariable = combobox2_str)
combobox2['values'] = ()
combobox2.set('')
combobox2.bind('<<ComboboxSelected>>')
# #combobox3ラベルの作成
label4_str = StringVar()
label4_str.set('分類(質的データ) >>')
label4 = ttk.Label(frame, textvariable = label4_str)
combobox3_str = StringVar()
combobox3 = ttk.Combobox(frame, width = 15, textvariable = combobox3_str)
combobox3['values'] = ()
combobox3.set('')
combobox3.bind('<<ComboboxSelected>>')
# #combobox4ラベルの作成
label5_str = StringVar()
label5_str.set('シート選択 >>')
label5 = ttk.Label(frame, textvariable = label5_str)
combobox4_str = StringVar()
combobox4 = ttk.Combobox(frame, width = 15, textvariable = combobox4_str)
combobox4['values'] = ()
combobox4.set('')
combobox4.bind('<<ComboboxSelected>>')
#ブールチェック用のチェックボタン作成
bool_check = tk.BooleanVar(value = True)
bool_check.set(False)
checkbutton = ttk.Checkbutton(frame, text = '標準化', variable = bool_check)
### 各種ウィジェットの設置
label1.grid(row = 0, column = 0)
file1_entry.grid(row = 0, column = 1)
button1.grid(row = 0, column = 2)
label5.grid(row = 0, column = 3)
combobox4.grid(row = 0, column = 4)
button4_execute.grid(row = 0, column = 5)
label3.grid(row = 1, column = 0)
combobox2.grid(row = 1, column = 1)
label2.grid(row = 1, column = 2)
combobox1.grid(row = 1, column = 3)
label4.grid(row = 1, column = 4)
combobox3.grid(row = 1, column = 5)
button1_execute.grid(row = 2, column = 0)
button2_execute.grid(row = 2, column = 1)
checkbutton.grid(row = 2, column = 2)
button3_execute.grid(row = 2, column = 5)
root.mainloop()かなり長いコードになっています。
関数やクラスを上手く使えばスッキリしたソースコードになるのでしょうが、私にはひとまず形にするので精一杯でした…。
とりあえず作ってみることが大切!と自分に言い聞かせております。
ツールの使用上の注意点
こちらのツールの使用上の注意点は3つです。
- 欠損値を含むデータ列は除外される
- 分析結果は「一時保存フォルダ」に保存されるため、データ容量に注意する
- データ分析後のファイル名が複雑なため、管理に工夫が必要
1. 欠損値データを含むカラムは除外される
例えば、下記のようなデータで分析を行うとします。
※赤枠部が欠損値(データとして不整合なもの)です。
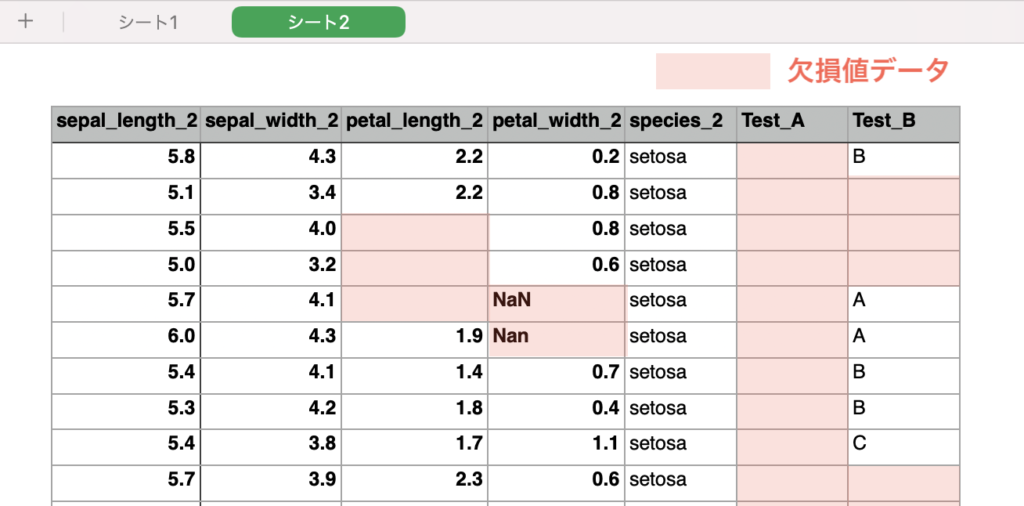
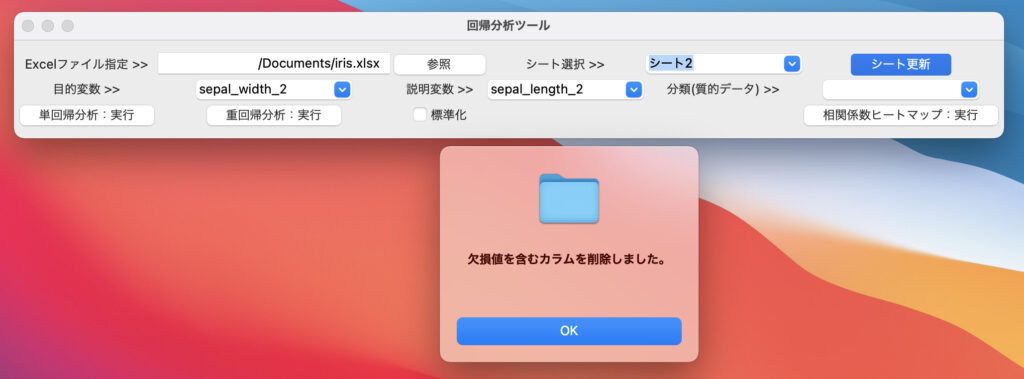
このデータシートを読み込むと、ポップアップが表示され、欠損値を含むデータは除外されるようになっています。

2. 一時保存フォルダ
分析結果は使用したエクセルが格納されているフォルダ内に、新しく一時保存フォルダを作成し、そこに格納するようにプログラムを作成しています。
そのため、徐々にデータ容量を圧迫しているということも起きかねないので、不要な場合は削除してください。
3. ファイルの管理
分析が単回帰分析・重回帰分析・相関係数ヒートマップ作成とあり、さらに設定変数によって様々な組み合わせが可能なため、必然的にファイル名が長くなっています。
そのため、同じフォルダ内に分析結果が多数保存されていると、ぱっと見ではどの条件か判断が難しいです。
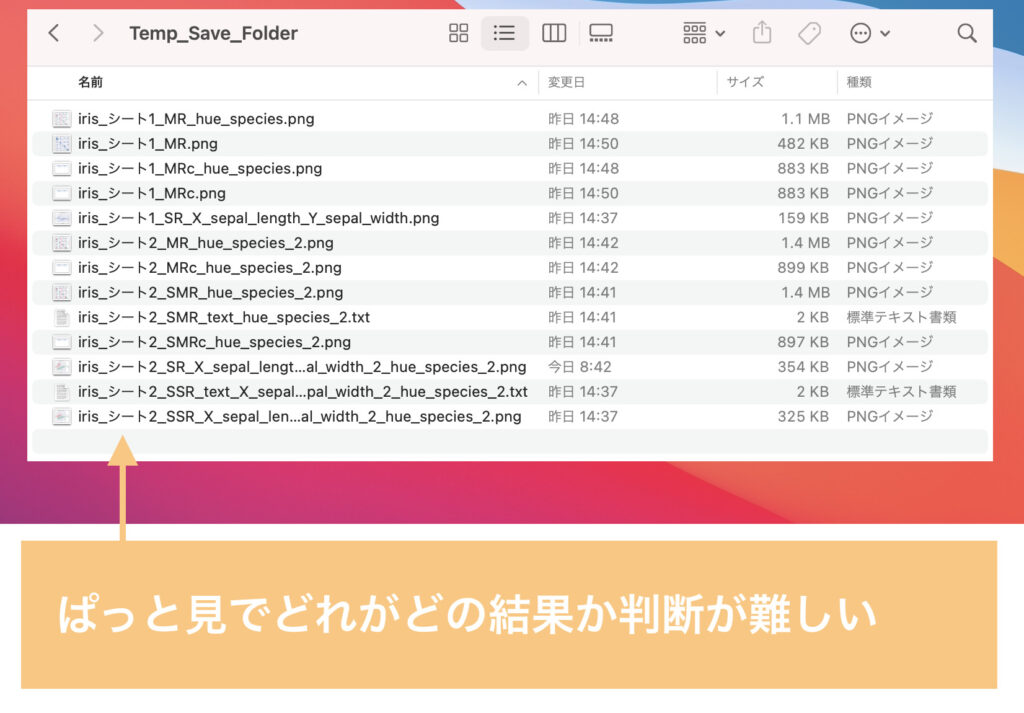
ちなみに、保存ファイル名には下記のようなルールを設定しています。
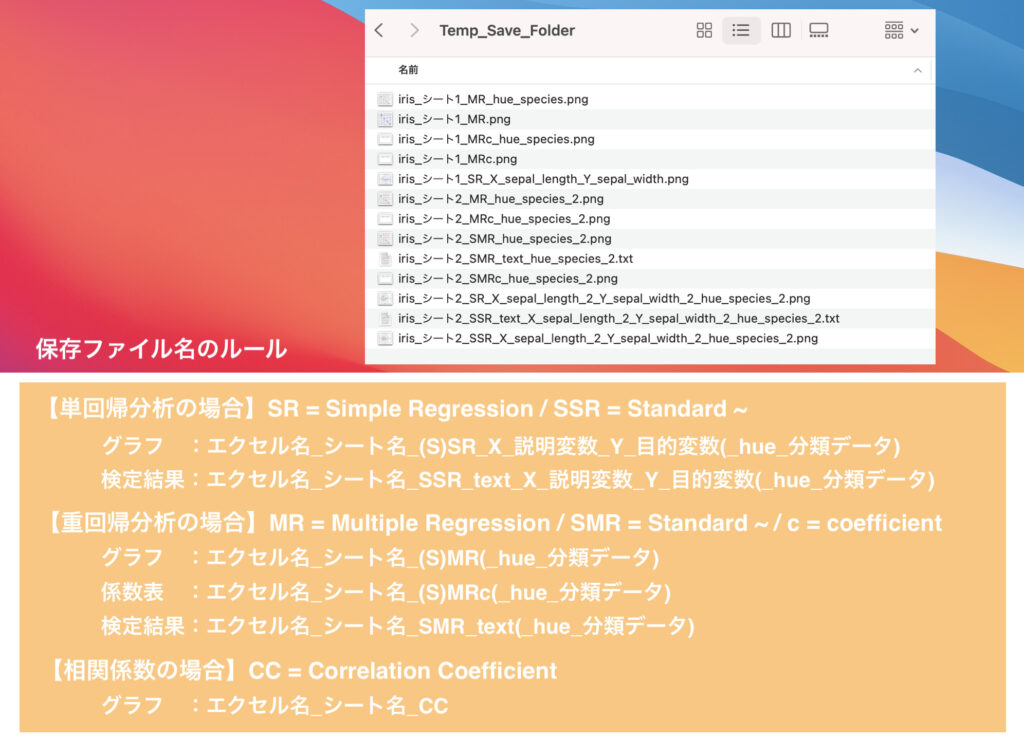
後で見る際に、どこにデータがあるか分からなくならないよう、ファイル管理には注意してください。
ツールの改善点
ツールを改善するとすれば、前述の注意点をふまえた下記があげられます。
- 欠損値を含む行だけを除外させる(現状はデータ列全てを削除)
- ファイル名を自由記述で付与する
- ソースコードのスッキリ化
私個人的には使用上で特に困る内容がないため、これらの改善点を修正しておりませんが、皆さんは使用上の用途に合わせてコード修正を行ってみてください。
また、私自身全ての不具合やエラーを発見できている訳ではないため、追加で発見した課題やより便利な機能があれば修正・更新していきたいと思います。
ツールを職場で展開する場合
こちらを業務効率化ツールとして展開する場合は、exeファイル化をしてください。
exe化することにより、展開された側のPCにpythonがインストールされていなくても、ツールを使用することができます。
このpyファイル(pythonの実行ファイル:.py)のexe化は2つの手順で完了します。
- pyinstallerをインストールする
- exe化のコマンドを実行する
まずは、pyinstallerというライブラリをインストールします。
インストールはコマンドプロンプトやターミナルで下記のコマンドを実行してください。
pip install pyinstallerインストールが完了したのちに、下記のコマンドを入力して実行してください。
pyinstaller (pyファイル名) --onefile --noconsole※上記コマンドの実行時は”()”は不要です
上記のコマンドを実行することにより、pyファイルのexe化ができます。
ちなみに、”–onefile”はexe化のファイルを1つにまとめて作成してくれるコマンドです。
入力していないと大量のファイルが出力されるので必須です。
また、”–noconsole”は実行時にコマンドプロンプトの画面を表示されなくするコマンドです。
exeファイルを実行したときに、コマンドプロンプトが表示されると不安になる方もいると思うので、忘れずに記述しましょう。
この他にも、Pythonで仕事の自動化をしたい時にオススメの参考書はこちら!


データ分析のツールを作ってみた感想
このツールを作成するに至った背景は、「データ分析が面倒」という想いからでした。
コードの書き方や、「もっとこうすればいいのに」というところが多々あるかもしれませんが、業務効率化や自動化ツールに興味のある方のご参考になれば幸いです。
使用していく中で、私も気づいていないエラーの発生等があるかもしれませんが、「こんな機能欲しい!」「こういう修正すればいいんじゃないか」という発見があれば、ぜひ共有いただけたら嬉しいです。
ご覧いただき、ありがとうございました!